You can download and install MySQL, followed by Navicat, a graphical user interface (GUI – ‘gooey’), from these sites:
Then Install Navicat Lite from here:
- In Navicat Lite click on Connection > MySQL to create a new connection.
- Give it any name you want, and leave ‘localhost’ as it is (this means your computer).
- Type the password you created for your MySQL databases in the password box.
- Click OK.
- Once you’ve created your connection you’ll notice, there are already a couple of databases – these were added when you installed MySQL.
- Ignore these, but right click either on the name of your connection or the databases and select ‘New Database’.
- Give it a name and click OK.
- You should now be able to see it alongside the other databases.
Importing Tables
- Open the Navicat Lite window.
- Highlight ‘Tables’ on the left hand column.
- The ‘Import Wizard’ will appear at the top.
- Start importing; follow instructions on screen.
When you first import a table for analysis, you will have to tick a few buttons in the Navicat window. Things to remember are the DATA TYPES that you can have for each column:
- VARCHAR can be text, character or string. If the table uses coding, for example 1 for female, 2 for male, you will want to consider this text, not number, that is, VARCHAR, not FLOAT.
- FLOAT – if you tick FLOAT, you are telling the computer the data in question is a number
- DATEs – check if dates on your dataset use the American or British format and select accordingly. Years can be entered as four or two digits, eg 18/07/2011 or 18/07/11.
- SELECT – tells you which columns or fields you are pulling data from.
- FROM – the name of the table the data is coming from. May be case sensitive.
- WHERE – is the criteria and works like a filter [eg =’NHS’ or =#01/05/2010# or >34 / For multiple criteria use AND. eg/ Category=’NHS’ AND Region=’England’]
- GROUP BY – is the aggregator
- HAVING – always used together with GROUP BY and is the second criteria after ag gregation
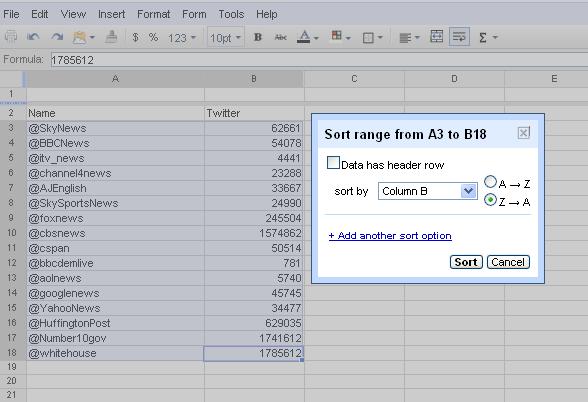
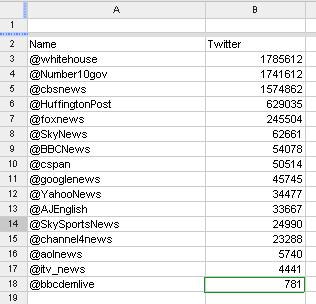
- ORDER BY – to sort your data; can be numeric or alphabetic
- Never bring in more columns into queries than necessary. Keep them as simple as you can.
- Queries are extremely literal: any spelling mistakes, spaces where there shouldn’t be one will affect results.
- To indicate you are expecting TEXT, use single quote mark (‘…’), eg ‘NHS’
- To indicate you are expecting a NUMBER, use NO PUNCTUATION.
- To indicate you are expectating a DATE, use hashmarks on both sides (#…#), eg #07/07/77#
- Use the wildcard (*) to indicate you want the query to consider everything, not specific columns/fields eg in SELECT
- Never make any changes in the original table. Keep it pristine.
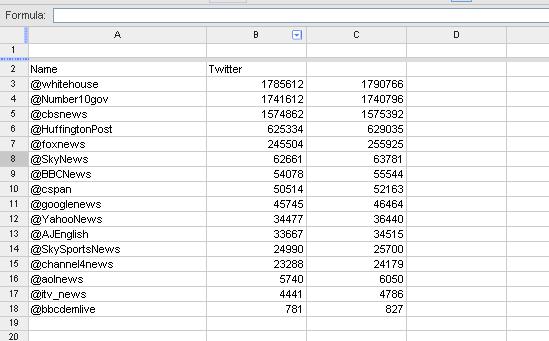
SUM(argument) – the ‘argument’ will be a column name, e.g. sum(debt) or sum(amount) [N.B.: no space between sum and the parentheses]
- SELECT last, rest, sum(amount) [= this means you want query results to show columns called last, rest and the sum of the amounts each person donated]
- FROM TENNGIVE [=name of table you are using]
- GROUP BY last, rest
- HAVING sum(amount) > 2000 [=you only want a list of people who contributed more than 2,000pounds/dollars for example]
- ORDER BY sum(amount) DESC [=you want the sum column ordered in descending order from high to low]
- or ORDER BY 3 DESC [=in which 3 indicates you want it to sort column 3]
- SELECT last, rest, occupation, sum(amount)
- FROM TENNGIVE
- WHERE last LIKE ‘hasl%’ or rest LIKE ‘%hasl%’ [This ensures people with Haslam in their last (last) OR middle names (rest) appear, even if misspelled]
- GROUP BY last, rest, occupation [Note that GROUP BY does not, and should not, include the function: sum(amount)]
- ORDER BY 3 DESC
- SELECT occupation, COUNT(occupation)
- FROM TENNGIVE
- GROUP BY occupation
- ORDER BY 2 DESC
COUNT(occupation) is the ‘argument’ here. But the problem with COUNT is that it does not include any NULLs, which completely skews the results of your query. To resolve this problem use COUNT(*), which counts everything, including nulls.
- Use TRIM in SELECT, eg. SELECT TRIM(occupation), COUNT(occupation)
- Use Google Refine, which you can download free onto your computer. The post Cleaning Data using Google Refine in the Online Journalism Blog may help.
- Other simple ways of cleaning data on an Excel sheet can be found here.
- MySQL is an open-source relational database system (RDBMS) owned by Oracle, with a freely available code source. It runs on all operating systems (OS).
- There is also another free RDBMS called SQL Server Express. The latest version is the 2008 one. Being a Microsoft product, SQL Server Express will only run on Windows but Mac users can download a (free) programme called MAMP (=Macintosh, Apache, MySQL and PHP).
- SQL Server is MySQL’s more full-bodied “big brother” but it comes at a cost.
- Both servers have their pluses and minuses. I found this SQL Authority.com blog post (N.B. bear in mind this post is from 2009) helpful.
David Donald says with MySQL there are no two ways: it’s “use it or lose it”. The best thing is to download it all and get practising.
- 1. MySQL Tutorial
- 2. Tutorials Point (includes a discussion forum)
- 3. Navicat support (for Windows, Mac and Linux)
- 1. Learning MySQL – O’Reilly Media
- 2. Learning SQL – O’Reilly Media
- 3. SQL Cookbook – O’Reilly Media
- 4. Learning SQL Server (helpful tutorials through blog posts and videos)
- 5. Understanding SQL by Martin Gruber
- 6. Sams Teach Yourself SQL in 24 Hours
Further SQL training
SQL is not an exclusive remit of journalists of course. Far from it. Anyone who works or analyses large datasets/databases can benefit from it. As a matter of fact, a few City workers attended the session alongside journalists and CAR enthusiasts like myself.